Chapter 12 Privacy and Confidentiality
Stefan Bender, Ron Jarmin, Frauke Kreuter, and Julia Lane
This chapter addresses the issue that sits at the core of any study of human beings—ensuring that the privacy and confidentiality of the people and organizations who are being studied is protected to the extent possible.
The challenge that is faced for researchers is that the goal of their work, unlike the private sector, must be to create value the public good and not for private gain. For that value to be realized, it is necessary that multiple researchers have access to the data so that results can be replicated, validated and extended. However, the more researchers access the data, the greater the risk that there is a breach of confidentiality. Social scientists have historically used two ways of minimizing that risk: anonymizing the data so that an individual’s information can’t be reidentified, and asking human subjects for the consent to the use their data (National Academies 2014). Those twin approaches have become obsolete, for reasons we will discuss in this chapter, and have not been replaced by an alternative framework. This concluding chapter identifies the issues that must be addressed for responsible research.
12.1 Introduction
Much social science research uses data on individuals, households, different types of businesses, and organizations like educational, and government institutions. Indeed, the example running throughout this book involves data on individuals (such as faculty and students) and organizations (such as universities and firms). In circumstances such as these, researchers must ensure that such data are used responsibly—that there is a clear understanding and attempt to mitigate the possible harm from such use. In practical terms, the study of human subjects requires that the interests of individual privacy and data confidentiality be balanced against the social benefits of research access and use.
We begin by defining terms.
Utility Data utility is the value resulting from data use. That utility has soared in the private sector—the biggest companies in the United States are data companies Amazon, Google, Microsoft, Facebook and Apple (Galloway 2017). They make their money by producing utility to their customers. The goal of social science research, to hark back to the first chapter, to use new data and tools to answer questions like
‘What are the earnings and employment outcomes of individuals graduating from two and four year colleges?’
‘How does placement in different types of firms change the likelihood of recidivism of formerly incarcerated workers?,’
and
- ‘How do regulatory agencies move from reactive, complaint-based, health and safety inspections for workplaces and housing to a more proactive approach that focuses on prevention?’
Privacy “encompasses not only the famous ‘right to be left alone,’ or keeping one’s personal matters and relationships secret, but also the ability to share information selectively but not publicly” (President’s Council of Advisors on Science and Technology 2014). A useful way of thinking about privacy is the notion of preserving the appropriate flow of information (Nissenbaum 2009). There is no specific data type or piece of information that is too sensitive to be shared in all circumstances. In some context providing detailed information about one’s health is very appropriate, for example if it helps finding the right treatment for a disease. It is generally important to understand the context and the contextual integrity of the data flow when deciding which data to collect and how to analyze and share them.
Confidentiality is “preserving authorized restrictions on information access and disclosure, including means for protecting personal privacy and proprietary information” (McCallister, Grance, and Scarfone 2010). Doing so is not easy—the challenge to the research community is how to balance the risk of providing access with the associated utility (Duncan, Elliot, and Juan Jose Salazar 2011). To give a simple example, if means and percentages are presented for a large number of people, it will be difficult to infer an individual’s value from such output, even if one knew that a certain individual or unit contributed to the formation of that mean or percentage. However, if those means and percentages are presented for subgroups or in multivariate tables with small cell sizes, the risk for disclosure increases (Doyle et al. 2001).
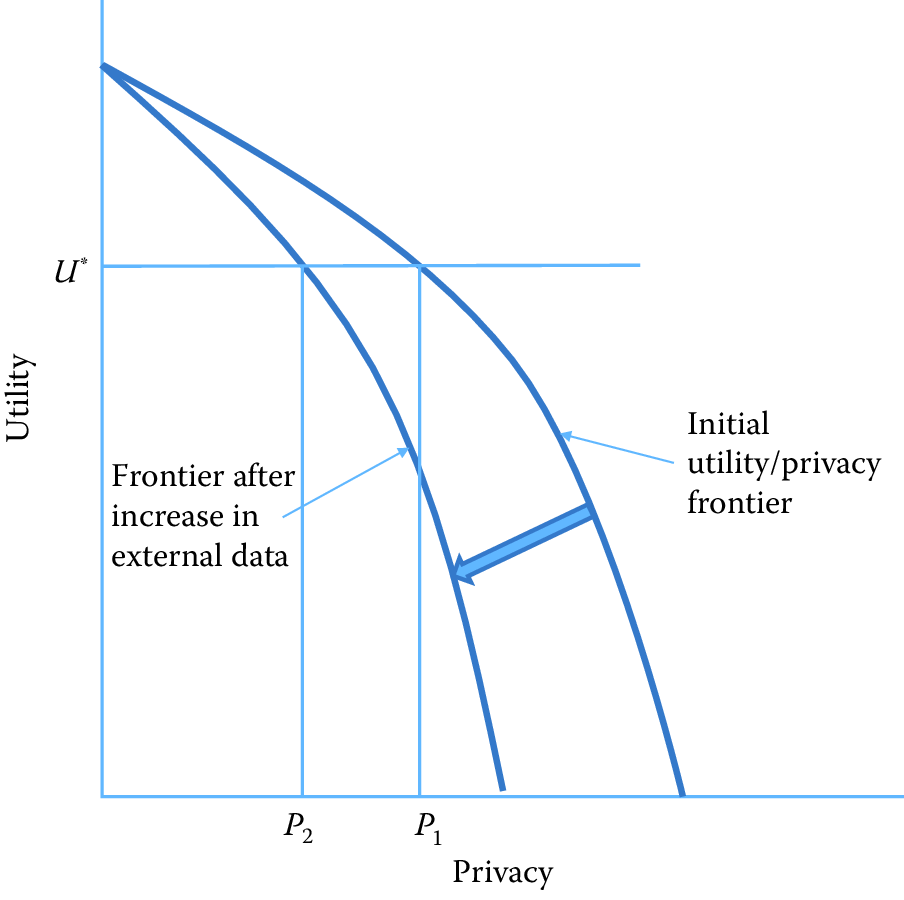
Figure 12.1: The privacy–utility tradeoff
Risk is generally thought of as the risk of an intruder reidentifying an individual or a business in a research dataset (Duncan and Stokes 2004). It is often argued that those risks increase every year as more and more data are available on individuals on the internet or in the databases of large corporations and as there are more and better tools available to make such linkages (Shlomo 2014, Herzog, Scheuren, and Winkler (2007)). However it could also be argued that the proliferation of data and tools reduces risk because it is so much easier for an intruder to find out information on an individual through a Google search (Lane 2020). Regardless, it is generally accepted that greater research access to data and their original values increases the risk of reidentification for individual units.
Harm Although much of the discussion of privacy and confidentiality has been driven by the imperatives of the legislation governing statistical agencies, which imposes civil and criminal penalties for any reidentification, statistical agencies no longer have a monopoly on data access and use. As a result, there is more attention being paid to the potential for harm based on the type of information being shared, rather than the fact that a piece of information is shared (Nissenbaum 2019). Intuitively, if an intruder finds out that an individual in a dataset is a woman, or is married, that may cause less harm than if information about income, sexual history, or criminal records are recovered.
There is an explicit tradeoff between data access and data utility. The greater the number of researchers and analysts that access the data, the greater the quality of the analysis and the greater the number of potential uses (Lane 2007). We depict this tradeoff graphically in Figure 12.1. The concave curves in this hypothetical example depict the technological relationship between data utility and privacy for an organization such as a business firm or a statistical agency. At one extreme, all information is available to anybody about all units, and therefore high analytic utility is associated with the data that are not at all protected. At the other extreme, nobody has access to any data and no utility is achieved. Initially, assume the organization is on the outer frontier. Increased external data resources (those not used by the organization) increase the risk of reidentification. This is represented by an inward shift of the utility/privacy frontier in Figure 12.1. Before the increase in external data, the organization could achieve a level of data utility \(U^*\) and privacy \(P_1\). The increase in externally available data now means that in order to maintain utility at \(U^*\), privacy is reduced to \(P_2\). This simple example represents the challenge to all organizations that release statistical or analytical products obtained from underlying identifiable data. As more data from external sources becomes available, it becomes more difficult to maintain privacy.
Previously, national statistical agencies had the capacity and the mandate to make dissemination decisions: they assessed the risk, they understood the data user community and the associated utility from data releases. And they had the wherewithal to address the legal, technical, and statistical issues associated with protecting confidentiality (Trewin et al. 2007).
But in a world of massive amounts of data, many once-settled issues have new complications, and wholly new issues arise that need to be addressed, albeit under the same rubrics. The new types of data have much greater potential utility, often because it is possible to study small cells or the tails of a distribution in ways not possible with small data. In fact, in many social science applications, the tails of the distribution are often the most interesting and hardest-to-reach parts of the population being studied; consider health care costs for a small number of ill people (Stanton and Rutherford 2006), or economic activity such as rapid employment growth by a small number of firms (Decker et al. 2016).
Example: The importance of activity in the tails
Spending on health care services in the United States is highly concentrated among a small proportion of people with extremely high use. For the overall civilian population living in the community, the latest data indicate that more than 20% of all personal health care spending in 2009 ($275 billion) was on behalf of just 1% of the population (Schoenman 2012).
It is important to understand the source of the risk of privacy breaches. Let us assume for a moment that we conducted a traditional small-scale survey with 1,000 respondents. The survey contains information on political attitudes, spending and saving in a given year, and income, as well as background variables on income and education. If name and address are saved together with this data, and someone gets access to the data, obviously it is easy to identify individuals and gain access to information that is otherwise not public. If the personal identifiable information (name and address) are removed from this data file, the risk is much reduced. If someone has access to the survey data and sees all the individual values, it might be difficult to assess with certainty which of the more than 330 million inhabitants in the USA is associated with an individual data record. However, the risk is higher if one knows some of this information (say, income) for a person, and knows that this person is in the survey. With these two pieces of information, it is likely possible to uniquely identify the person in the survey data.
Larger amounts of data increase the risk precisely for this reason. Much data is available for reidentification purposes (Ohm 2010). Most obviously, the risk of reidentification is much greater because the new types of data have much richer detail and a much larger public community has access to ways to reidentify individuals. There are many famous examples of reidentification occurring even when obvious personal information, such as name and social security number, has been removed and the data provider thought that the data were consequently deidentified. In the 1990s, Massachusetts Group Insurance released “deidentified” data on the hospital visits of state employees; researcher Latanya Sweeney quickly reidentified the hospital records of the then Governor William Weld using nothing more than state voter records about residence and date of birth (Sweeney 2001). In 2006, the release of supposedly de-identified web search data by AOL resulted in two New York Times reports being able to reidentify a customer simply from her browsing habits (Barbaro, Zeller, and Hansell 2006). And in 2012, statisticians at the department store, Target, used a young teenager’s shopping patterns to determine that she was pregnant before her father did (Hill 2012).
But there are also less obvious problems. What is the legal framework when the ownership of data is unclear? In the past, when data were more likely to be collected and used within the same entity—for example, within an agency that collects administrative data or within a university that collects data for research purposes—organization-specific procedures were (usually) in place and sufficient to regulate the usage of these data. Today, legal ownership is less clear (Lane et al. 2014). There are many unresolved issues, such as Who has the legal authority to make decisions about permission, access, and dissemination and under what circumstances?. The challenge today is that data sources are often combined, collected for one purpose, and used for another. Data providers often have a poor understanding of whether or how their data will be used. Think, for example, about cell phone calls. The New York Times has produced a series of thought-provoking articles about the access to and use of cell-phone data, such as the one entitled Your Apps Know Where You Were Last Night, and They’re Not Keeping It Secret (Valentino-DeVries et al. 2018). Who owns your cell phone calls? Should it be you, as the initiator of the call, your friend as the recipient, your cell phone company, your friend’s cell phone company, the cloud server on which the data are stored for billing purposes, or the satellite company that connects the two of you? And what laws should regulate access and use? The state (or country) that you’re in when you make the call? Or your friend’s state (or country)? The state (or country) of your cell phone provider? And so on. The legal framework is, at best, murky.
Example: Knowledge is power
In a discussion of legal approaches to privacy in the context of big data, Strandburg (2014) says: “‘Big data’ has great potential to benefit society. At the same time, its availability creates significant potential for mistaken, misguided or malevolent uses of personal information. The conundrum for the law is to provide space for big data to fulfill its potential for societal benefit, while protecting citizens adequately from related individual and social harms. Current privacy law evolved to address different concerns and must be adapted to confront big data’s challenges.”
12.2 Why is access important?
This chapters in this book have provided detailed examples of the potential of data to provide insights into a variety of social science questions—particularly the relationship between investments in R&D and innovation. But that potential is only realized if researchers have access to the data (Lane 2007): not only to perform primary analyses but also to validate the data generation process (in particular, data linkage), replicate analyses, and build a knowledge infrastructure around complex data sets.
Validating the data generating process
Research designs requiring a combination of data sources and/or analysis of the tails of populations challenge the traditional paradigm of conducting statistical analysis on deidentified or aggregated data. In order to combine data sets, someone in the chain that transforms raw data into research outputs needs access to link keys contained in the data sets to be combined. High-quality link keys uniquely identify the subjects under study and typically are derived from items such as individual names, birth dates, social security numbers, and business names, addresses, and tax ID numbers. From a privacy and confidentiality perspective, link keys are among the most sensitive information in many data sets of interest to social scientists. This is why many organizations replace link keys containing personal identifiable information (PII)99 with privacy-protecting identifiers (Schnell, Bachteler, and Reiher 2009). Regardless, at some point in the process those must be generated out of the original information, thus access to the latter is important.
Replication
John Ioannidis has claimed that most published research findings are false (Ioannidis 2005); for example, the unsuccessful replication of genome-wide association studies, at less than 1%, is staggering (Bastian 2013). Inadequate understanding of coverage, incentive, and quality issues, together with the lack of a comparison group, can result in biased analysis—famously in the case of using administrative records on crime to make inference about the role of death penalty policy in crime reduction (Donohue III and Wolfers 2006; Levitt and Miles 2006). Similarly, overreliance on, say, Twitter data, in targeting resources after hurricanes can lead to the misallocation of resources towards young, Internet-savvy people with cell phones and away from elderly or impoverished neighborhoods (Shelton et al. 2014), just as bad survey methodology led the Literary Digest to incorrectly call the 1936 election (Squire 1988). The first step to replication is data access; such access can enable other researchers to ascertain whether the assumptions of a particular statistical model are met, what relevant information is included or excluded, and whether valid inferences can be drawn from the data (Kreuter and Peng 2014).
Building knowledge infrastructure
Creating a community of practice around a data infrastructure can result in tremendous new insights, as the Sloan Digital Sky Survey and the Polymath project have shown (Nielsen 2012). In the social science arena, the Census Bureau has developed a productive ecosystem that is predicated on access to approved external experts to build, conduct research using, and improve key data assets such as the Longitudinal Business Database (Jarmin and Miranda 2002) and Longitudinal Employer Household Dynamics (Abowd, Haltiwanger, and Lane 2004), which have yielded a host of new data products and critical policy-relevant insights on business dynamics (Haltiwanger, Jarmin, and Miranda 2013) and labor market volatility (Brown, Haltiwanger, and Lane 2008), respectively. Without providing robust, but secure, access to confidential data, researchers at the Census Bureau would have been unable to undertake the innovations that made these new products and insights possible.
12.3 Providing access
The approaches to providing access have evolved over time. Statistical agencies often employ a range of approaches depending on the needs of heterogeneous data users (Doyle et al. 2001; Foster, Jarmin, and Riggs 2009). Dissemination of data to the public usually occurs in three steps: an evaluation of disclosure risks, followed by the application of an anonymization technique, and finally an evaluation of disclosure risks and analytical quality of the candidate data release(s). The two main approaches have been statistical disclosure control techniques to produce anonymized public use data sets, and controlled access through a research data center (Shlomo 2018).
Statistical disclosure control techniques
Statistical agencies have made data available in a number of ways: through tabular data, public use files, licensing agreements and, more recently, through synthetic data (Reiter 2012). Hundepool et al. (Hundepool et al. 2010) define statistical disclosure control as follows:
concepts and methods that ensure the confidentiality of micro and aggregated data that are to be published. It is methodology used to design statistical outputs in a way that someone with access to that output cannot relate a known individual (or other responding unit) to an element in the output.
Traditionally, confidentiality protection was accomplished by releasing only aggregated tabular data. This practice worked well in settings where the primary purpose was enumeration, such as census taking. However, tabular data are poorly suited to describing the underlying distributions and covariance across variables that are often the focus of applied social science research (Duncan, Elliot, and Juan Jose Salazar 2011).
To provide researchers access to data that permitted analysis of the underlying variance–covariance structure of the data, some agencies have constructed public use micro-data samples. To product confidentiality in such public use files, a number of statistical disclosure control procedures are typically applied. These include stripping all identifying (e.g., PII) fields from the data, topcoding highly skewed variables (e.g., income), and swapping records (Doyle et al. 2001; Zayatz 2007). However, the mosaic effect—where disparate pieces of information can be combined to reidentify individuals—dramatically increases the risk of releasing public use files (Czajka et al. 2014). In addition, there is more and more evidence that the statistical disclosure procedure applied to produce them decreases their utility across many applications (Burkhauser, Feng, and Larrimore 2010).
Some agencies provide access to confidential micro-data through licensing arrangements. A contract specifies the conditions of use and what safeguards must be in place. In some cases, the agency has the authority to conduct random inspections. However, this approach has led to a number of operational challenges, including version control, identifying and managing risky researcher behavior, and management costs (Doyle et al. 2001).
Another approach to providing access to confidential data that has been proposed by a group of theoretical computer scientists Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith (2014). Here statistics or other reported outputs are injected with noise, and are called “differentially private” if the inclusion or exclusion of the most at-risk person in the population does not change the probability of any output by more than a given factor. The parameter driving this factor (usually referred to as epsilon) quantifies how sensitive the aggregate output is to any one person’s data. If it is low, the output is highly “private” in the sense that it will be very difficult to reconstruct anything based on it. If it is high, reconstruction is easy. For a discussion of the applications to Census data see (Ruggles et al. 2019; Abowd 2018).
Although the research agenda is an interesting and important one, there are a number of concerns about the practical implications. The Census Bureau, for example, has spent many millions of dollars to implement differential privacy techniques for the 2020 Decennial Census, and researchers who have studied the potential impact on small towns worry that small towns will “disappear” from official statistics—a major issue when data are used for decision-making (Wezerek and Van Riper 2020).
Another approach that has had some resurgence is the use of synthetic data where certain properties of the original data are preserved but the original data are replaced by “synthetic data” so that no individual or business entity can be found in the released data (Drechsler 2011). One of the earlier examples of such work was the IBM Quest system (Agrawal and Srikant 1994) that generated synthetic transaction data. Two more recent examples of synthetic data sets are the SIPP Synthetic-Beta (Abowd, Stinson, and Benedetto 2006) of linked Survey of Income and Program Participation (SIPP) and Social Security Administration earnings data, and the Synthetic Longitudinal Business Database (SynLBD) (Kinney et al. 2011). Jarmin et al. (2014) discuss how synthetic data sets lack utility in many research settings but are useful for generating flexible data sets underlying data tools and apps such as the Census Bureau’s OnTheMap. It is important to keep in mind that the utility of synthetic data sets as a general purpose “anonymization” tool is fairly limited. Synthetic data generation typically requires explicitly defining which properties of the original data need to be preserved (such as univariate or bivariate distributions of certain variables), and as such can be of limited use in most social science research.
Research data centers
The second approach is establishing research data centers (RDC). RDC present an established operational approach to facilitate access to confidential microdata for research and/or statistical purposes. This approach is based on the theoretical framework of the “Five Safes” which was initially developed by Felix Ritchie at the UK Office of National Statistics in 2003 (Desai, Ritchie, and Welpton 2016). The first dimension refers to safe projects. This dimension mainly refers to the whether the intended use of the data conforms with the use specified in legislations or regulations. For example, a legislation may specifically allow users to use the data only for independent scientific research. Safe people, the second dimension of the Five Saves framework, requires data users to be able to use the data in an appropriate way. A certain amount of technical skills or minimum educational levels may be required to access the data. In contrast, safe data refers to the potential to de-identifying individuals or entities in the data. Safe settings relate to the practical controls on how the data are accessed. Different channels may exist which in turn may depend on the de-identification risk. In practice, the lower the de-identification risk the more restrictive the setting will be. Lastly, safe output refers to the risk of de-identification in publications from confidential microdata. Strong input and output controls are in place to ensure that published findings comply with the privacy and confidentiality regulations (Hayden 2012).
Box: Federal Statistical Research Data Centers
It is not easy to use the FSRDCs. Every stage of the research process is significantly more time-consuming than using public use data, and only the most persistent researchers are successful. In addition, most of the branches charge high fees for anyone unaffiliated with an institution sponsoring an FSRDC. Projects are approved only if they benefit the Census Bureau, which by itself makes most research topics ineligible. Prospective users must prepare detailed proposals, including the precise models they intend to run and the research outputs they hope to remove from the center, which are generally restricted to model coefficients and supporting statistics. Most descriptive statistics are prohibited. Researchers are not allowed to “browse” the data or change the outputs based on their results. Under census law, researchers must become (unpaid) Census Bureau employees to gain access to non-public data. To meet this requirement, once a project is approved researchers must obtain Special Sworn Status, which involves a level 2 security clearance and fingerprint search. Applicants must be U.S. citizens or U.S. residents for three years, so most international scholars are excluded. Researchers then undergo data stewardship training. If researchers wish to modify their original model specifications or outputs, they must submit a written request and wait for approval. When the research is complete, the results must be cleared before publication by the Center for Disclosure Avoidance Research at the Census Bureau. Any deviations from the original proposal must be documented, justified, and approved. The FSRDCs were never intended as a substitute for public use microdata, and they cannot fulfill that role. Even if the number of seats in the centers could be multiplied several hundred-fold to accommodate the current number of users of public use data, substantial hurdles remain. Applying for access and gaining approval to use the FSRDC takes at least six months and usually more. Eligibility for using FSRDCs is limited to investigators (a) affiliated with an FSRDC (or with significant financial resources), (b) with sufficient time to wait for review and approvals, and (c) doing work deemed valuable by the Bureau (UnivTask Force on Differential Privacy for Census Data 2019).
Box: The Administrative Data Research Facility
There are other approaches that are becoming available. The Commission on Evidence-based Policy identified new technologies, such as remote access, cloud-based, virtual data facilities, as a promising approach to provide scalable secure access to microdata without the disadvantages of the bricks and mortar approached used by the FSRDC system. One such approach, the Administrative Data Research Facility has incorporated the “five safes” principles—safe projects, safe people, safe settings, safe data, and safe outputs (https://en.wikipedia.org/wiki/Five_safes)---into its design. In addition to winning a Government Innovation Award (Government Computer News Staff 2018), it has been used to provide secure access to confidential data to over 450 government analysts and researchers in the past 3 years (Kreuter, Ghani, and Lane 2019).
12.4 Non-Tabular data
In addition to tabular data, many new sources of data consist of text, audio, image, and video content. The above approaches primarily deal with maintaining the privacy and confidentiality of entities in tabular data but it is equally important to do the same in non-tabular data. Medical records, sensitive crime records, notes and comments in administrative records, camera footage (from police body-cams or security cameras for example) are all examples of data that is being used for analysis and requires robust techniques to maintain the privacy and confidentiality of individuals. Although the techniques there are not as mature, there is some work in these areas:
Text Anonymization: Typical approaches here range from simply removing Personally identifiable information (PII) through regular expressions and dictionaries (Neamatullah et al. 2008) to machine learning based approaches that balance the confidentiality of the entities in the data and the utility of the text (Cumby and Ghani 2011).
Image and Video Anonymization: The most common use of anonymization techniques in image and video data is to redact, blur, or remove faces of individuals in order to protect their identity. This can be extended to other attributes of the person, such as clothing or the rest of the body but the primary focus so far has been on detecting, and then blurring or modifying the faces of individuals in the data. Sah et al. (2017) provide a survey of video redaction methods. Hukkelas et al. (2019) recently presented a method to automatically anonymize faces in images while retaining the original data distribution.
12.5 The new challenges
While there are well-established policies and protocols surrounding access to and use of survey and administrative data, a major new challenge is the lack of clear guidelines governing the collection of data about human activity in a world in which all public, and some private, actions generate data that can be harvested (President’s Council of Advisors on Science and Technology 2014; Ohm 2010; Strandburg 2014). The twin pillars on which so much of social science have rested—informed consent and anonymization—are virtually useless in a big data setting where multiple data sets can be and are linked together using individual identifiers by a variety of players beyond social scientists with formal training and whose work is overseen by institutional review boards. This rapid expansion in data and their use is very much driven by the increased utility of the linked information to businesses, policymakers, and ultimately the taxpayer. In addition, there are no obvious data stewards and custodians who can be entrusted with preserving the privacy and confidentiality with regard to both the source data collected from sensors, social media, and many other sources, and the related analyses (Lane and Stodden 2013).
It is clear that informed consent as historically construed is no longer feasible. As Nissenbaum (2011) points out, notification is either comprehensive or comprehensible, but not both. While ideally human subjects are offered true freedom of choice based on a sound and sufficient understanding of what the choice entails, in reality the flow of data is so complex and the interest in the data usage so diverse that simplicity and clarity in the consent statement unavoidably result in losses of fidelity, as anyone who has accepted a Google Maps agreement is likely to understand (Hayden 2015). In addition, informed consent requires a greater understanding of the breadth of type of privacy breaches, the nature of harm as diffused over time, and an improved valuation of privacy in the big data context. Consumers may value their own privacy in variously flawed ways. They may, for example, have incomplete information, or an overabundance of information rendering processing impossible, or use heuristics that establish and routinize deviations from rational decision-making (Acquisti 2014).
It is also nearly impossible to truly anonymize data. Big data are often structured in such a way that essentially everyone in the file is unique, either because so many variables exist or because they are so frequent or geographically detailed, that they make it easy to reidentify individual patterns (Narayanan and Shmatikov 2008). It is also no longer possible to rely on sampling or measurement error in external files as a buffer for data protection, since most data are not in the hands of statistical agencies.
There are no data stewards controlling access to individual data. Data are often so interconnected (think social media network data) that one person’s action can disclose information about another person without that person even knowing that their data are being accessed. The group of students posting pictures about a beer party is an obvious example, but, in a research context, if the principal investigator grants access to the proposal, information could be divulged about colleagues and students. In other words, volunteered information of a minority of individuals can unlock the same information about many—a type of “tyranny of the minority” (Barocas and Nissenbaum 2014b).
There are particular issues raised by the new potential to link information based on a variety of attributes that do not include PII. Barocas and Nissenbaum write as follows (Barocas and Nissenbaum 2014a):
Rather than attempt to deanonymize medical records, for instance, an attacker (or commercial actor) might instead infer a rule that relates a string of more easily observable or accessible indicators to a specific medical condition, rendering large populations vulnerable to such inferences even in the absence of PII. Ironically, this is often the very thing about big data that generate the most excitement: the capacity to detect subtle correlations and draw actionable inferences. But it is this same feature that renders the traditional protections afforded by anonymity (again, more accurately, pseudonymity) much less effective.
In light of these challenges, Barocas and Nissenbaum continue
the value of anonymity inheres not in namelessness, and not even in the extension of the previous value of namelessness to all uniquely identifying information, but instead to something we called “reachability,” the possibility of knocking on your door, hauling you out of bed, calling your phone number, threatening you with sanction, holding you accountable—with or without access to identifying information.
It is clear that the concepts used in the larger discussion of privacy and big data require updating. How we understand and assess harms from privacy violations needs updating. And we must rethink established approaches to managing privacy in the big data context. The next section discusses the framework for doing so.
12.6 Legal and ethical framework
The Fourth Amendment to the US Constitution, which constrains the government’s power to “search” the citizenry’s “persons, houses, papers, and effects” is usually cited as the legal framework for privacy and confidentiality issues. In the US a “sectoral” approach to privacy regulation, for example, the Family Education Rights and Privacy Act through commercial transactions with a business, and hence is not covered by these frameworks. There are major questions as to what is reasonably private and what constitutes unwarranted intrusion (Strandburg 2014). There is a lack of clarity on who owns the new types of data—whether it is the person who is the subject of the information, the person or organization who collects these data (the data custodian), the person who compiles, analyzes, or otherwise adds value to the information, the person who purchases an interest in the data, or society at large. The lack of clarity is exacerbated because some laws treat data as property and some treat it as information (Cecil and Eden 2003).
The ethics of the use of big data are also not clear, because analysis may result in being discriminated against unfairly, being limited in one’s life choices, being trapped inside stereotypes, being unable to delineate personal boundaries, or being wrongly judged, embarrassed, or harassed. There is an entire research agenda to be pursued that examines the ways that big data may threaten interests and values, distinguishes the origins and nature of threats to individual and social integrity, and identifies different solutions (Boyd and Crawford 2012). The approach should be to describe what norms and expectations are likely to be violated if a person agrees to provide data, rather than to describe what will be done during the research.
What is clear is that most data are housed no longer in statistical agencies, with well-defined rules of conduct, but in businesses or administrative agencies. In addition, since digital data can be alive forever, ownership could be claimed by yet-to-be-born relatives whose personal privacy could be threatened by release of information about blood relations.
The new European Data Protection Regulation (GDPR), which is in effect since May, 2018, was designed to address some of the challenges. In addition to ensuring lawful data collection practices, GDPR pushes for purpose limitation and data minimisation. This principle requires organisations to clearly state for what purpose personal data is collected, to collect the data only for the time needed to complete the purpose, and to collect only those personal data that is needed to achieve the specified processing purposes. In the U.S. the California Consumer Privacy Act (CCPA) is in effect since January 2020, and here too companies have now have time limits to process customer data.
However, GDPR and other regulations of this type, still rely on traditional regulatory tools for managing privacy, which is notice, and consent. Both have failed to provide a viable market mechanism allowing a form of self-regulation governing industry data collection. Going forward, a more nuanced assessment of tradeoffs in the big data context, moving away from individualized assessments of the costs of privacy violations, is needed (Strandburg 2014).
Ohm advocates for a new conceptualization of legal policy regarding privacy in the big data context that uses five guiding principles for reform: first, that rules take into account the varying levels of inherent risk to individuals across different data sets; second, that traditional definitions of PII need to be rethought; third, that regulation has a role in creating and policing walls between data sets; fourth, that those analyzing big data must be reminded, with a frequency in proportion to the sensitivity of the data, that they are dealing with people; and finally, that the ethics of big data research must be an open topic for continual reassessment (Ohm 2014).
12.7 Summary
The excitement about how big data can change the social science research paradigm should be tempered by a recognition that existing ways of protecting privacy confidentiality are no longer viable (Karr and Reiter 2014). There is a great deal of research that can be used to inform the development of such a structure, but it has been siloed into disconnected research areas, such as statistics, cybersecurity, and cryptography, as well as a variety of different practical applications, including the successful development of remote access secure data enclaves. We must piece together the knowledge from these various fields to develop ways in which vast new sets of data on human beings can be collected, integrated, and analyzed while protecting them (Lane et al. 2014).
It is possible that the confidentiality risks of disseminating data may be so high that traditional access models will no longer hold; that the data access model of the future will be to take the analysis to the data rather than the data to the analyst or the analyst to the data. One potential approach is to create an integrated system including (a) unrestricted access to highly redacted data, most likely some version of synthetic data, followed by (b) means for approved researchers to access the confidential data via remote access solutions, combined with (c) verification servers that allows users to assess the quality of their inferences with the redacted data so as to be more efficient with their use (if necessary) of the remote data access. Such verification servers might be a web-accessible system based on a confidential database with an associated public micro-data release, which helps to analyze the confidential database (Karr and Reiter 2014). Such approaches are starting to be developed, both in the USA and in Europe (Elias 2014; Jones and Elias 2006).
There is also some evidence that people do not require complete protection, and will gladly share even private information provided that certain social norms are met (Wilbanks 2014; Pentland et al. 2014). There is a research agenda around identifying those norms as well; characterizing the interests and wishes of actors (the information senders and recipients or providers and users); the nature of the attributes (especially types of information about the providers, including how these might be transformed or linked); and identifying transmission principles (the constraints underlying the information flows).
However, it is likely that it is no longer possible for a lone social scientist to address these challenges. One-off access agreements to individuals are conducive to neither the production of high-quality science nor the high-quality protection of data (Schermann et al. 2014). The curation, protection, and dissemination of data on human subjects cannot be an artisan activity but should be seen as a major research infrastructure investment, like investments in the physical and life sciences (Bird 2011; Abazajian et al. 2009; Human Microbiome Jumpstart Reference Strains Consortium et al. 2010). In practice, this means that linkages become professionalized and replicable, research is fostered within research data centers that protect privacy in a systematic manner, knowledge is shared about the process of privacy protections disseminated in a professional fashion, and there is ongoing documentation about the value of evidence-based research. It is thus that the risk–utility tradeoff depicted in Figure 12.1 can be shifted in a manner that serves the public good.
12.8 Resources
The American Statistical Association’s Privacy and Confidentiality website provides a useful source of information.100
An overview of federal activities is provided by the Confidentiality and Data Access Committee of the Federal Committee on Statistics and Methodology.101
The World Bank and International Household Survey Network provide a good overview of data dissemination “best practices.”102
There is a Journal of Privacy and Confidentiality based at Carnegie Mellon University103, and also a journal called Transactions in Data Privacy104.
The United Nations Economic Commission on Europe hosts workshops and conferences and produces occasional reports.105
Collection of lectures from the semester on privacy at the Simons Institute for the Theory of Computing.106
References
Abazajian, Kevork N., Jennifer K. Adelman-McCarthy, Marcel A. Agüeros, Sahar S. Allam, Carlos Allende Prieto, Deokkeun An, Kurt S. J. Anderson, et al. 2009. “The Seventh Data Release of the Sloan Digital Sky Survey.” Astrophysical Journal Supplement Series 182 (2). IOP Publishing.
Abowd, John M. 2018. “The US Census Bureau Adopts Differential Privacy.” In Proceedings of the 24th Acm Sigkdd International Conference on Knowledge Discovery & Data Mining., 2867–7. ACM.
Abowd, John M., John Haltiwanger, and Julia Lane. 2004. “Integrated Longitudinal Employer-Employee Data for the United States.” American Economic Review 94 (2): 224–29.
Abowd, John M., Martha Stinson, and Gary Benedetto. 2006. “Final Report to the Social Security Administration on the SIPP/SSA/IRS Public Use File Project.” Suitland, MD: Census Bureau, Longitudinal Employer-Household Dynamics Program.
Acquisti, Alessandro. 2014. “The Economics and Behavioral Economics of Privacy.” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Stefan Bender, and Helen Nissenbaum, 98–112. Cambridge University Press.
Agrawal, Rakesh, and Ramakrishnan Srikant. 1994. “Fast Algorithms for Mining Association Rules in Large Databases.” In Proceedings of the 20th International Conference on Very Large Data Bases.
Barbaro, Michael, Tom Zeller, and Saul Hansell. 2006. “A Face Is Exposed for AOL Searcher No. 4417749.” New York Times, August.
Barocas, Solon, and Helen Nissenbaum. 2014a. “Big Data’s End Run Around Procedural Privacy Protections.” Communications of the ACM 57 (11). ACM: 31–33.
Barocas, Solon, and Helen Nissenbaum. 2014b. “The Limits of Anonymity and Consent in the Big Data Age.” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Stefan Bender, and Helen Nissenbaum. Cambridge University Press.
Bastian, Hilda. 2013. “Bad Research Rising: The 7th Olympiad of Research on Biomedical Publication.” https://blogs.scientificamerican.com/absolutely-maybe/bad-research-rising-the-7th-olympiad-of-research-on-biomedical-publication/ Accessed February 1, 2020.
Bird, Ian. 2011. “Computing for the Large Hadron Collider.” Annual Review of Nuclear and Particle Science 61. Annual Reviews: 99–118.
Boyd, Danah, and Kate Crawford. 2012. “Critical Questions for Big Data: Provocations for a Cultural, Technological, and Scholarly Phenomenon.” Information, Communication & Society 15 (5). Taylor & Francis: 662–79.
Brown, Clair, John Haltiwanger, and Julia Lane. 2008. Economic Turbulence: Is a Volatile Economy Good for America? University of Chicago Press.
Burkhauser, Richard V., Shuaizhang Feng, and Jeff Larrimore. 2010. “Improving Imputations of Top Incomes in the Public-Use Current Population Survey by Using Both Cell-Means and Variances.” Economics Letters 108 (1). Elsevier: 69–72.
Cecil, Joe, and Donna Eden. 2003. “The Legal Foundations of Confidentiality.” In Key Issues in Confidentiality Research: Results of an NSF Workshop. National Science Foundation.
Cumby, Chad, and Rayid Ghani. 2011. “A Machine Learning Based System for Semi-Automatically Redacting Documents.” AAAI Publications, Twenty-Third IAAI Conference.
Czajka, John, Craig Schneider, Amang Sukasih, and Kevin Collins. 2014. “Minimizing Disclosure Risk in HHS Open Data Initiatives.” US Department of Health & Human Services.
Decker, Ryan A., John Haltiwanger, Ron S. Jarmin, and Javier Miranda. 2016. “Where Has All the Skewness Gone? The Decline in High-Growth (Young) Firms in the US.” European Economic Review 86: 4–23.
Desai, T., F. Ritchie, and R. Welpton. 2016. “Five Safes: Designing Data Access for Research.” Working Papers 20161601, Department of Accounting, Economics; Finance, Bristol Business School, University of the West of England, Bristol.
Donohue III, John J., and Justin Wolfers. 2006. “Uses and Abuses of Empirical Evidence in the Death Penalty Debate.” National Bureau of Economic Research.
Doyle, Pat, Julia I. Lane, Jules J. M. Theeuwes, and Laura V. Zayatz. 2001. Confidentiality, Disclosure, and Data Access: Theory and Practical Applications for Statistical Agencies. Elsevier Science.
Drechsler, Jörg. 2011. Synthetic Datasets for Statistical Disclosure Control: Theory and Implementation. Springer.
Duncan, George T, and S Lynne Stokes. 2004. “Disclosure Risk Vs. Data Utility: The Ru Confidentiality Map as Applied to Topcoding.” Chance 17 (3). Taylor & Francis: 16–20.
Duncan, George T., Mark Elliot, and Gonzalez Juan Jose Salazar. 2011. Statistical Confidentiality: Principles and Practice. Springer.
Dwork, Cynthia, and Aaron Roth. 2014. “The Algorithmic Foundations of Differential Privacy.” Foundations and Trends in Theoretical Computer Science 9 (3–4): 211–407.
Elias, Peter. 2014. “A European Perspective on Research and Big Data Access.” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Stefan Bender, and Helen Nissenbaum, 98–112. Cambridge University Press.
Foster, Lucia, Ron S. Jarmin, and T. Lynn Riggs. 2009. “Resolving the Tension Between Access and Confidentiality: Past Experience and Future Plans at the US Census Bureau.” 09-33. US Census Bureau Center for Economic Studies.
Galloway, Scott. 2017. The Four: The Hidden DNA of Amazon, Apple, Facebook and Google. Random House.
Government Computer News Staff. 2018. “Data mashups at government scale: The Census Bureau ADRF.” GCN Magazine.
Haltiwanger, John, Ron S. Jarmin, and Javier Miranda. 2013. “Who Creates Jobs? Small Versus Large Versus Young.” Review of Economics and Statistics 95 (2). MIT Press: 347–61.
Hayden, Erica Check. 2015. “Researchers Wrestle with a Privacy Problem.” Nature 525 (7570).
Hayden, Erika Check. 2012. “A Broken Contract.” Nature 486 (7403): 312–14.
Herzog, Thomas N., Fritz J. Scheuren, and William E. Winkler. 2007. Data Quality and Record Linkage Techniques. Springer Science & Business Media.
Hill, Kashmir. 2012. “How Target Figured Out a Teen Girl Was Pregnant Before Her Father Did.” Forbes, http://www.forbes.com/sites/kashmirhill/2012/02/16/how-target-figured-out-a-teen-girl-was-pregnant-before-her-father-did/#7280148734c6.
Hukkelas, Hakon, Rudolf Mester, and Frank Lindseth. 2019. “DeepPrivacy: A Generative Adversarial Network for Face Anonymization.” https://arxiv.org/abs/1909.04538.
Human Microbiome Jumpstart Reference Strains Consortium, K. E. Nelson, G. M. Weinstock, and others. 2010. “A Catalog of Reference Genomes from the Human Microbiome.” Science 328 (5981). American Association for the Advancement of Science: 994–99.
Hundepool, Anco, Josep Domingo-Ferrer, Luisa Franconi, Sarah Giessing, Rainer Lenz, Jane Longhurst, E. Schulte Nordholt, Giovanni Seri, and P. Wolf. 2010. “Handbook on Statistical Disclosure Control.” Network of Excellence in the European Statistical System in the Field of Statistical Disclosure Control.
Ioannidis, John P. A. 2005. “Why Most Published Research Findings Are False.” PLoS Medicine 2 (8): e124.
Jarmin, Ron S., and Javier Miranda. 2002. “The Longitudinal Business Database.” Available at SSRN: https://ssrn.com/abstract=2128793.
Jarmin, Ron S., Thomas A. Louis, and Javier Miranda. 2014. “Expanding the Role of Synthetic Data at the US Census Bureau.” Statistical Journal of the IAOS 30 (2): 117–21.
Jones, Paul, and Peter Elias. 2006. “Administrative Data as a Research Resource: A Selected Audit.” ESRC National Centre for Research Methods.
Karr, Alan, and Jerome P. Reiter. 2014. “Analytical Frameworks for Data Release: A Statistical View.” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Stefan Bender, and Helen Nissenbaum. Cambridge University Press.
Kinney, Satkartar K., Jerome P. Reiter, Arnold P. Reznek, Javier Miranda, Ron S. Jarmin, and John M. Abowd. 2011. “Towards Unrestricted Public Use Business Microdata: The Synthetic Longitudinal Business Database.” International Statistical Review 79 (3). Wiley Online Library: 362–84.
Kreuter, Frauke, and Roger D. Peng. 2014. “Extracting Information from Big Data: Issues of Measurement, Inference, and Linkage.” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Stefan Bender, and Helen Nissenbaum, 257–75. Cambridge University Press.
Kreuter, Frauke, Rayid Ghani, and Julia Lane. 2019. “Change Through Data: A Data Analytics Training Program for Government Employees.” Harvard Data Science Review 1 (2).
Lane, Julia. 2007. “Optimizing Access to Micro Data.” Journal of Official Statistics 23: 299–317.
Lane, Julia. 2020. “Tiered Access: Risk and Utility.” Washington DC: Committee of Professional Associations on Federal Statistics (COPAFS).
Lane, Julia, and Victoria Stodden. 2013. “What? Me Worry? What to Do About Privacy, Big Data, and Statistical Research.” AMSTAT News 438. American Statistical Association: 14.
Lane, Julia, Victoria Stodden, Stefan Bender, and Helen Nissenbaum, eds. 2014. Privacy, Big Data, and the Public Good: Frameworks for Engagement. Cambridge: Cambridge University Press.
Levitt, Steven D., and Thomas J. Miles. 2006. “Economic Contributions to the Understanding of Crime.” Annual Review of Law Social Science 2. Annual Reviews: 147–64.
McCallister, Erika, Timothy Grance, and Karen A Scarfone. 2010. SP 800-122. Guide to Protecting the Confidentiality of Personally Identifiable Information (PII). National Institute of Standards; Technology.
Narayanan, Arvind, and Vitaly Shmatikov. 2008. “Robust de-Anonymization of Large Sparse Datasets.” In IEEE Symposium on Security and Privacy, 111–25. IEEE.
National Academies. 2014. “Proposed Revisions to the Common Rule for the Protection of Human Subjects in the Behavioral and Social Sciences.” Washington DC: National Academies of Sciences.
Neamatullah, Ishna, Margaret M. Douglass, Li-wei H. Lehman, Andrew Reisner, Mauricio Villarroel, William J. Long, Peter Szolovits, George B. Moody, Roger G. Mark, and Gari D. Clifford. 2008. “Automated de-Identification of Free-Text Medical Records.” BMC Medical Informatics and Decision Making 8.
Nielsen, Michael. 2012. Reinventing Discovery: The New Era of Networked Science. Princeton University Press.
Nissenbaum, Helen. 2009. Privacy in Context: Technology, Policy, and the Integrity of Social Life. Stanford University Press.
Nissenbaum, Helen. 2011. “A Contextual Approach to Privacy Online.” Daedalus 140 (4). MIT Press: 32–48.
Nissenbaum, Helen. 2019. “Contextual Integrity up and down the Data Food Chain.” Theoretical Inquiries in Law 20 (1). De Gruyter: 221–56.
Ohm, Paul. 2010. “Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization.” UCLA Law Review 57: 1701.
Ohm, Paul. 2014. “The Legal and Regulatory Framework: What Do the Rules Say About Data Analysis?” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Helen Nissenbaum, and Stefan Bender. Cambridge University Press.
Pentland, Alex, Daniel Greenwood, Brian Sweatt, Arek Stopczynski, and Yves-Alexandre de Montjoye. 2014. “Institutional Controls: The New Deal on Data.” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Stefan Bender, and Helen Nissenbaum, 98–112. Cambridge University Press.
President’s Council of Advisors on Science and Technology. 2014. “Big Data and Privacy: A Technological Perspective.” Washington, DC: Executive Office of the President.
Reiter, Jerome P. 2012. “Statistical Approaches to Protecting Confidentiality for Microdata and Their Effects on the Quality of Statistical Inferences.” Public Opinion Quarterly 76 (1). AAPOR: 163–81.
Ruggles, Steven, Catherine Fitch, Diana Magnuson, and Jonathan Schroeder. 2019. “Differential Privacy and Census Data: Implications for Social and Economic Research.” AEA Papers; Proceedings (Vol. 109, pp. 403-08).
Sah, Shagan, Ameya Shringi, Raymond Ptucha, Aaron M. Burry, and Robert P. Loce. 2017. “Video Redaction: A Survey and Comparison of Enabling Technologies.” Journal of Electronic Imaging 26 (5): 1–14.
Schermann, Michael, Holmer Hemsen, Christoph Buchmüller, Till Bitter, Helmut Krcmar, Volker Markl, and Thomas Hoeren. 2014. “Big Data.” Business & Information Systems Engineering 6 (5). Springer: 261–66.
Schnell, Rainer, Tobias Bachteler, and Jörg Reiher. 2009. “Privacy-Preserving Record Linkage Using Bloom Filters.” BMC Medical Informatics and Decision Making 9 (1). BioMed Central Ltd: 41.
Schoenman, Julie A. 2012. “The Concentration of Health Care Spending.” NIHCM Foundation Data Brief. National Institute for Health Care Management.
Shelton, Taylor, Ate Poorthuis, Mark Graham, and Matthew Zook. 2014. “Mapping the Data Shadows of Hurricane Sandy: Uncovering the Sociospatial Dimensions of ‘Big Data’.” Geoforum 52. Elsevier: 167–79.
Shlomo, Natalie. 2014. “Probabilistic Record Linkage for Disclosure Risk Assessment.” In International Conference on Privacy in Statistical Databases, 269–82. Springer.
Shlomo, Natalie. 2018. “Statistical Disclosure Limitation: New Directions and Challenges.” Journal of Privacy and Confidentiality 8 (1).
Squire, Peverill. 1988. “Why the 1936 Literary Digest Poll Failed.” Public Opinion Quarterly 52 (1). AAPOR: 125–33.
Stanton, Mark W, and MK Rutherford. 2006. The High Concentration of Us Health Care Expenditures. Agency for Healthcare Research; Quality.
Strandburg, Katherine J. 2014. “Monitoring, Datafication and Consent: Legal Approaches to Privacy in the Big Data Context.” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Stefan Bender, and Helen Nissenbaum. Cambridge University Press.
Sweeney, Latanya. 2001. “Computational Disclosure Control: A Primer on Data Privacy Protection.” MIT.
Trewin, D., A. Andersen, T. Beridze, L. Biggeri, I. Fellegi, and T. Toczynski. 2007. “Managing Statistical Confidentiality and Microdata Access: Principles and Guidelines of Good Practice.” Geneva: Conference of European Statisticians, United Nations Economic Commision for Europe.
UnivTask Force on Differential Privacy for Census Data. 2019. “Implications of Differential Privacy for Census Bureau Data and Scientific Research.” Minneapolis, MN, USA: Institute for Social Research; Data Innovation, University of Minnesota.
Valentino-DeVries, Josephine, Natasha Singer, Michael Keller, and Aaron Krolick. 2018. “Your Apps Know Where You Were Last Night, and They’re Not Keeping It Secret.” New York, New York, USA.
Wezerek, Gus, and David Van Riper. 2020. “Changes to the Census Could Make Small Towns Disappear.” New York, New York, USA.
Wilbanks, John. 2014. “Portable Approaches to Informed Consent and Open Data.” In Privacy, Big Data, and the Public Good: Frameworks for Engagement, edited by Julia Lane, Victoria Stodden, Stefan Bender, and Helen Nissenbaum, 98–112. Cambridge University Press.
Zayatz, Laura. 2007. “Disclosure Avoidance Practices and Research at the US Census Bureau: An Update.” Journal of Official Statistics 23 (2). Statistics Sweden (SCB): 253–65.
PII is “any information about an individual maintained by an agency, including (1) any information that can be used to distinguish or trace an individual’s identity, such as name, social security number, date and place of birth, mother’s maiden name, or biometric records; and (2) any other information that is linked or linkable to an individual, such as medical, educational, financial, and employment information” (McCallister, Grance, and Scarfone 2010).↩
https://simons.berkeley.edu/programs/privacy2019, available on youtube: https://www.youtube.com/user/SimonsInstitute/.↩